Learning High-Speed Flight in the Wild.
Created 2021.10.26 by William Yu; Last modified: 2022.08.09-V1.2.2
Contact: windmillyucong@163.com
Copyleft! 2022 William Yu. Some rights reserved.
Learning High-Speed Flight in the Wild
University of Zurich and Intel
refitem:
- project page: http://rpg.ifi.uzh.ch/AgileAutonomy.html
- code: https://github.com/uzh-rpg/agile_autonomy
- paper: http://rpg.ifi.uzh.ch/docs/Loquercio21_Science.pdf
KeyWords
Quadrotors, Autonomously fly
Abstract
-
State-of-the-art methods:
- generally separate the navigation problem into subtasks: sensing, mapping, and planning.
-
Bugs:
- Although this approach has proven successful at low speeds, the separation it builds supon can be problematic for high-speed navigation in cluttered environments. 低速可以,高速不行。
- 为什么不行?: The subtasks are executed sequentially, leading to increased processing latency and a compounding of errors through the pipeline.
-
Debug:
-
Here we propose an end-to-end approach that can autonomously fly quadrotors through complex natural and human-made environments at high speeds, with purely onboard sensing and computation. 端到端的方法。
-
Our Solution: The key principle is to directly map noisy sensory observations to collision-free trajectories in a receding-horizon fashion.
-
Advantage: This direct mapping drastically reduces processing latency and increases robustness to noisy and incomplete perception.
-
How: The sensorimotor mapping is performed by a convolutional network that is trained exclusively in simulation via privileged learning: imitating an expert with access to privileged information.
感觉运动映射由卷积网络执行,该网络通过特权学习在模拟中专门训练:模仿可访问特权信息的专家。
-
Result:
- By simulating realistic sensor noise, our approach achieves zero-shot transfer直接转换 from simulation to challenging real-world environments that were never experienced during training: dense forests, snow-covered terrain, derailed trains, and collapsed buildings. 仿真结果可以0成本转换到真实环境。
- Our work demonstrates that end-to-end policies trained in simulation enable high-speed autonomous flight through challenging environments, outperforming traditional obstacle avoidance pipelines. 优于传统的障碍物躲避流程。
-
1. INTRODUCTION
Quadrotors
- are among the most agile and dynamic machines
- 简单介绍四旋翼飞行器,灌水凑字数
Problem
- Autonomous agile flight in arbitrary unknown environments. 本文致力于解决的问题:任意未知环境下的自主敏捷飞行
Approaches
-
Some works tackle only perception and build high-quality maps from imperfect measurements [5–9]. 有些工作只处理感知和构建来自不完美测量的高质量地图 [5-9]
-
whereas others focus on planning without considering perception errors [10–13]. 而其他专注于规划而不考虑感知错误 [10-13]
-
Numerous systems that combine online mapping with traditional planning algorithms have been proposed to achieve autonomous flight in previously unknown environments [14–22].
-
A taxonomy of prior works is presented in Figure S5 in the Supplementary Materials. 补充材料: 现有方法的分类
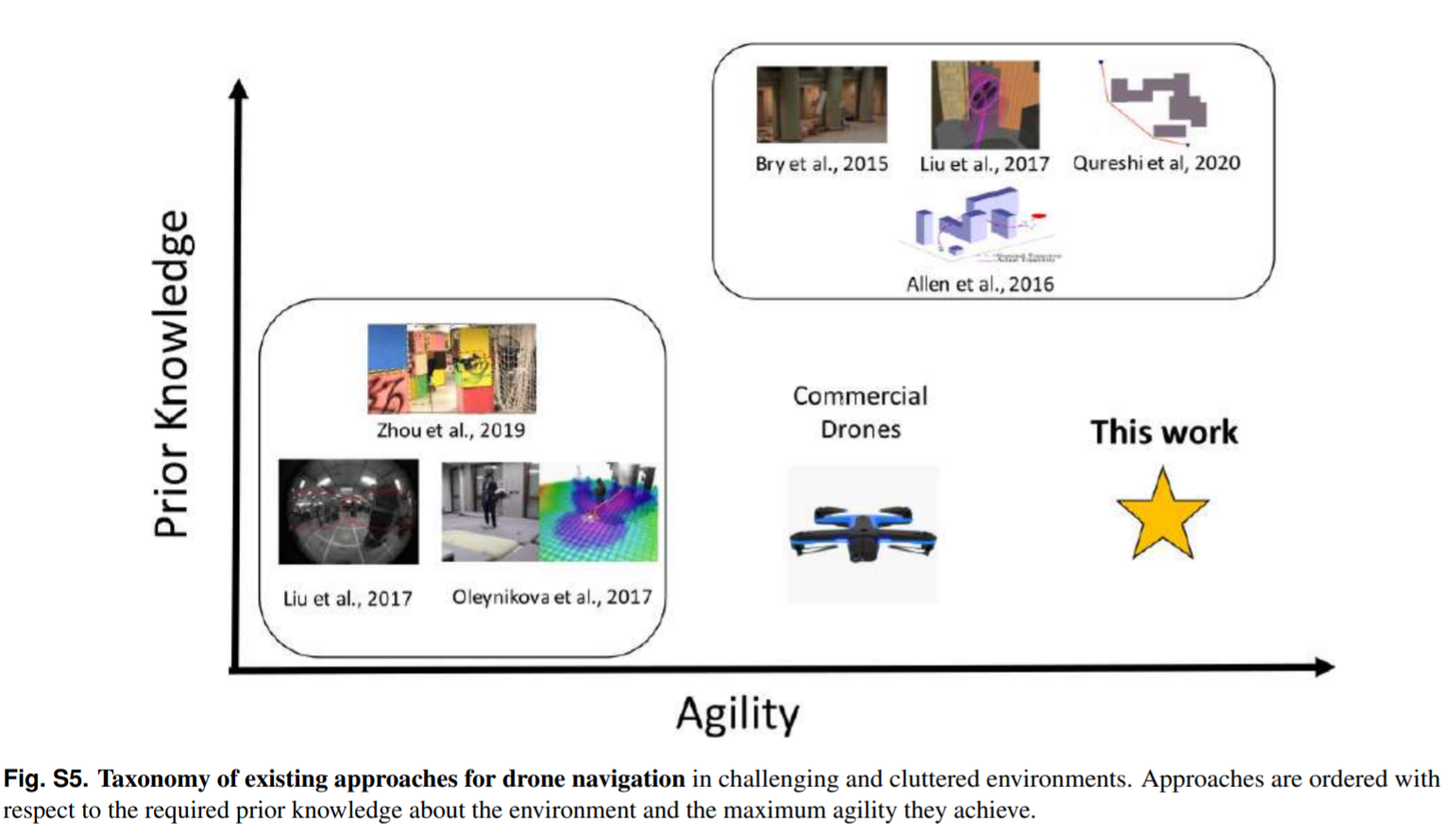
Analysis
- 传统方法 traditional pipelines
- The division of the navigation task into the mapping and planning subtasks is attractive from an engineering perspective, because it enables parallel progress on each component and makes the overall system interpretable. However, it leads to pipelines that largely neglect interactions between the different stages and thus compound errors [22]. Their sequential nature also introduces additional latency, making high-speed and agile maneuvers difficult to impossible [4]. While these issues can be mitigated to some degree by careful handtuning and engineering, the divide-and-conquer principle that has been prevalent in research on autonomous flight in unknown environments for many years imposes fundamental limits on the speed and agility that a robotic system can achieve [23].
- 近期工作 recent work
- In contrast to these traditional pipelines, some recent works propose to learn end-to-end policies directly from data without explicit mapping and planning stages [24–27]. These policies are trained by imitating a human [24, 27], from experience that was collected in simulation [25], or directly in the real world [26]. Because the number of samples required to train general navigation policies is very high, existing approaches impose constraints on the quadrotor’s motion model, for example by constraining the platform to planar motion [24, 26, 27] and/or discrete actions [25], at the cost of reduced maneuverability and agility. More recent work has demonstrated that very agile control policies can be trained in simulation [28]. Policies produced by the last approach can successfully perform acrobatic maneuvers, but can only operate in unobstructed free space and are essentially blind to obstacles in the environment.
- Our approach
- 略,详见后文
2. RESULTS
略
3. DISCUSSION
略
4. MATERIALS AND METHODS
- 3大部分
- A. The privileged expert
- B. The student policy
- C. Training environments
- System overview:
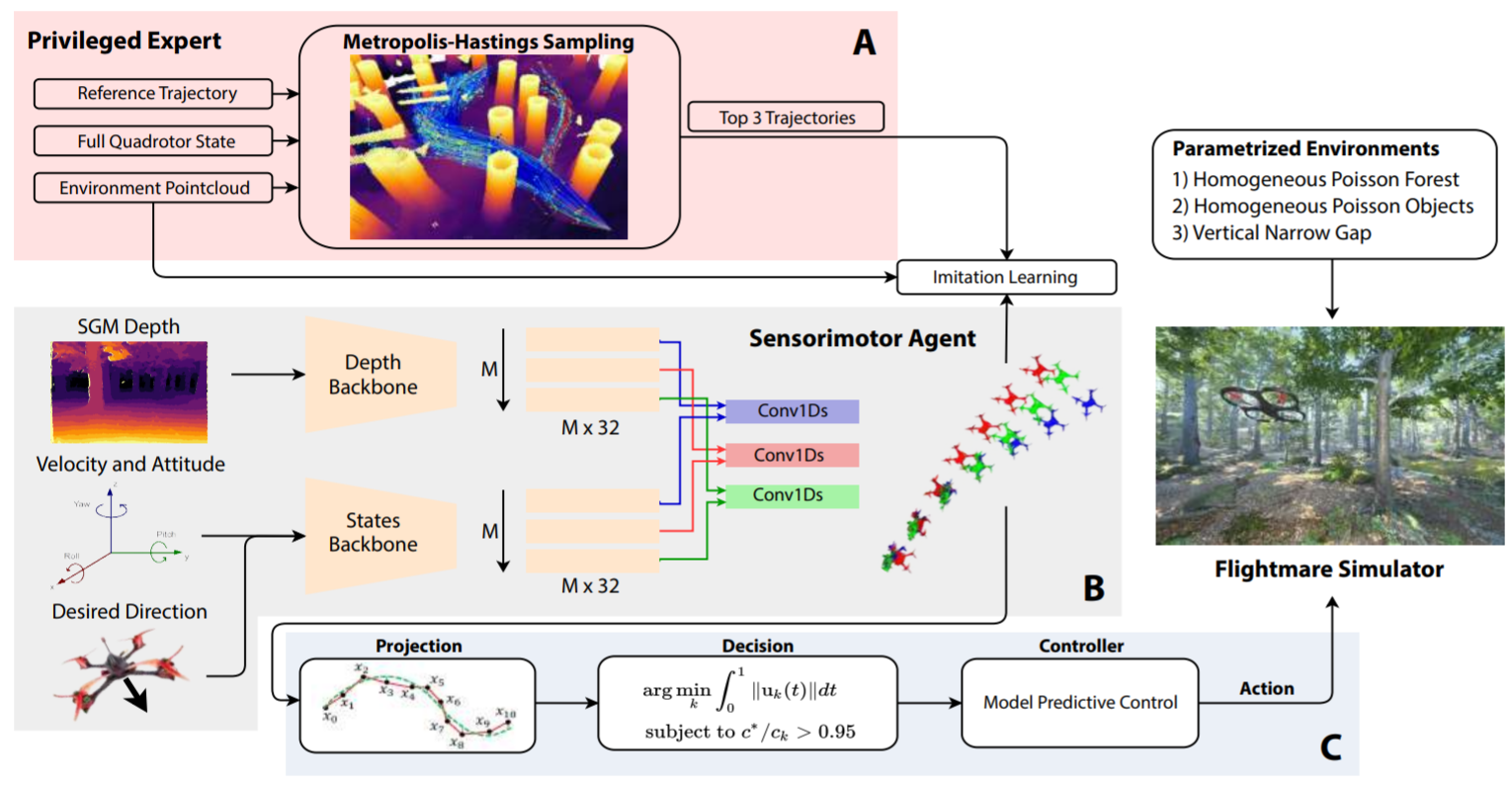
A. The privileged expert
- Our privileged expert is a sampling-based motion planning algorithm.
这部分对应的代码详见 traj_sampler/traj_sampler.cpp
Part 1
-
The expert generates a set of collision-free trajectories $τ$ representing the desired state of the quadrotor $x_{des} ∈ R^{13}$ (pos, vel, acc, att) over the next second, starting from the current state of the drone, i.e. $τ(0) = x$. 从当前位置生成一组无碰撞轨迹。
-
To do so, it samples from a probability distribution P that encodes 1.distance from obstacles and 2.proximity to the reference trajectory. 如何生成?两方面1.与障碍物的距离;2. 与设定参考轨迹的接近程度。
-
Specifically, the distribution of collision-free trajectories $P(τ | τ_{ref}, C)$ is conditioned on the reference trajectory $τ_{ref}$ and the structure of the environment in the form of a point cloud $C ∈ R^{n×3}$. 输入:参考轨迹,环境点云。
-
According to $P$, the probability of a trajectory τ is large if far from obstacles and close to the reference $τ_{ref}$. 设计思路:越贴合目标轨迹P越大,越远离障碍物P越大。
-
We define P as the following:

-
where c() is the trajectory cost function. We define the trajectory cost function as

-
where $C_{collision}$ is the collision cost function.
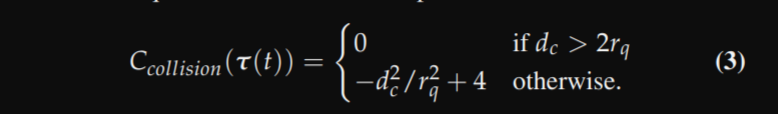
We model the quadrotor as a sphere of radius $r_{q}$ = 0.2 m
-
目标:以上3式, 求出P。
Part 2
-
New Problem:
The distribution P is complex. The analytical computation of P is generally intractable. P的分布太过复杂,无法求出。
-
Solution:
-
To approximate the density P, the expert uses random sampling. 随机抽样,离散化。
-
M-H algorithm
-
We point the interested reader to the Supplementary Materials (section S6), for an overview of the M-H algorithm and its convergence criteria.
文章内的附录 http://rpg.ifi.uzh.ch/docs/Loquercio21_Science.pdf#page=20&zoom=100,420,654%20%20section%20S6
-
refitem:
-
-
To approximate the density P, the expert uses random sampling. We generate samples with the M-H algorithm [41] as it provides asymptotic convergence guarantees to the true distribution. To estimate P, the M-H algorithm requires a target score function $ s(τ) ∝ P(τ | τref, C) $. We define s(τ) = exp(−c(τ, τref, C)), where c(·) is the cost of the trajectory τ. It is easy to show that this definition satisfies the conditions for the M-H algorithm to asymptotically estimate the target distribution P. Hence, the trajectories sampled with M-H will asymptotically cover all of the different modes of P. We point the interested reader to the Supplementary Materials (section S6), for an overview of the M-H algorithm and its convergence criteria.
-
-
对应的代码详见函数
TrajSampler::computeLabelBSplineSamplin()里面关键字main loop for Metropolis-Hastings.
Part 3
- New Problem: To decrease the dimension of the sampling space, 降维
- Solution: we use a compact yet expressive representation of the trajectories τ. We represent τ as a cubic B-spline τbspline ∈ IR3×3 curve with three control points and a uniform knot vector, enabling interpolation with high computational efficiency [42]. 在做sampling的时候,使用具有三个控制点和统一节点向量的三次B样条曲线。
- Advantage:
- Cubic B-splines are twice continuously differentiable and have a bounded derivative in a closed interval.
- Because of the differential flatness property of quadrotors [43], continuous and bounded acceleration directly translates to continuous attitude over the trajectory duration. This encourages dynamically feasible trajectories that can be tracked by a model-predictive controller accurately [43, 44].
- 对应的代码详见函数:
TrajSampler::sampleAnchorPoint()
Part 4
-
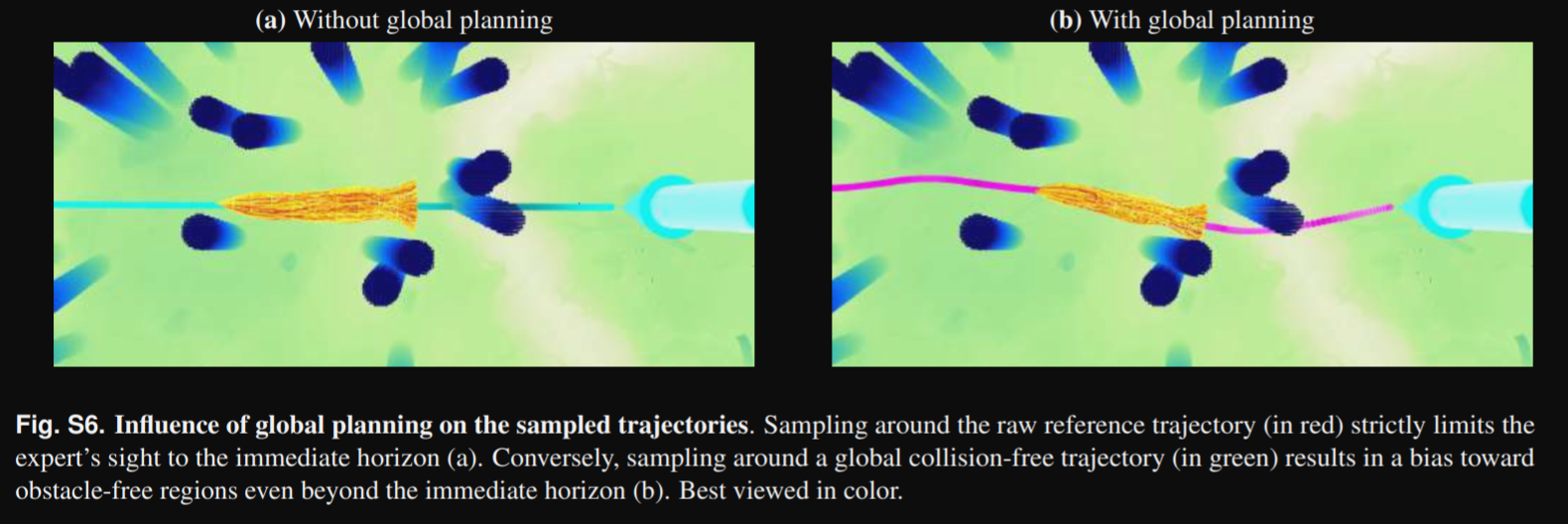
Tips: To bias the sampled trajectories toward obstacle-free regions, we replace the raw reference trajectory $τ_{ref}$ in Equation 2 with a global collision-free trajectory $τ_{gbl}$ from start to goal, that we compute using the approach of Liu et al. [13]. As illustrated in Figure S6, conditioning sampling on τgbl practically increases the horizon of the expert and generates more conservative trajectories. An animation explaining our expert is available in Movie 1. After removing all generated trajectories in collision with obstacles, we select the three best trajectories with lower costs. Those trajectories are used to train the student policy. 简单总结:使用地图先做全局规划,而后将全局规划的轨迹交给Local作为reference轨迹。
B. The student policy
C. Training environments
D. Method validation
实际实验,略
Contact
Feel free to contact me windmillyucong@163.com anytime for anything.